이제까지 공간 정보를 다루면서 가장 기초적인 부분들에 대해 내가 공부한 만치, 그리고 가능한 한 자세하게 설명하려고 했고 이제 여기까지 해서 크게 하나의 꼭지가 마무리될 것 같다.

Natural Breaks?
내추럴 브레이크란 지난 글에서 잠시 언급했을 텐데, 공간 정보가 눈에 잘 들어오게 하기 위한 방법 중에 하나라고 했었다. 사실은 이런 질문에서 시작한다.
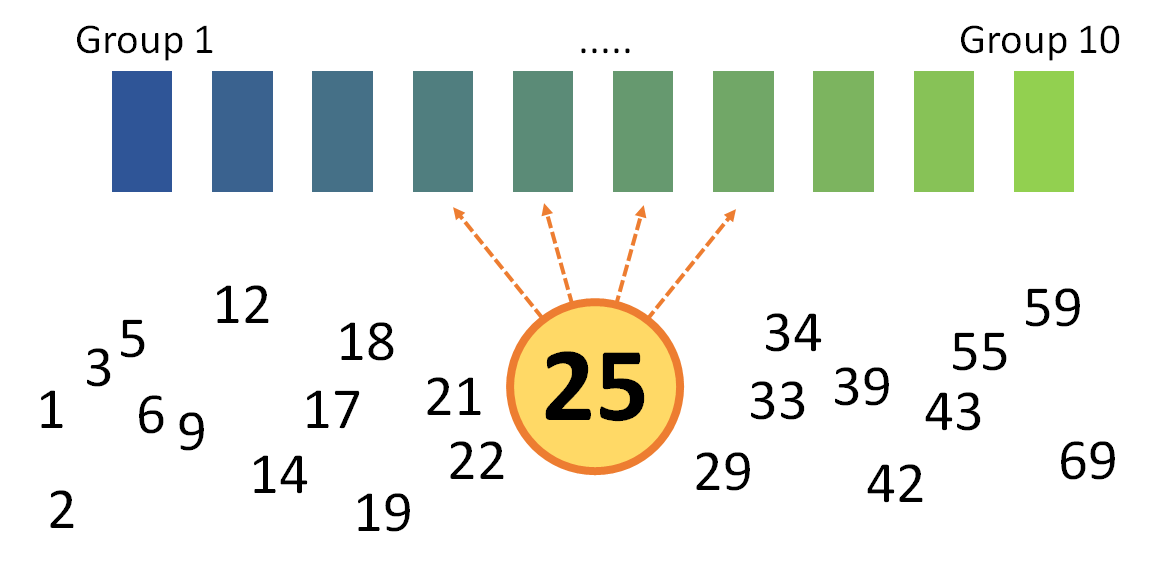
위처럼 산발적으로 배치된 숫자들을 10개의 그룹으로 분류한다고 생각해보자. 그러면 각 숫자들은 어느 그룹으로 끼어 들어가야 가장 "올바른" 분류가 될까? 이렇게 분류된 그룹을 색깔로 나타내면 그것이 바로 시각화가 될 것이다.
이건 사실 "올바른" 이라는 말이 잘못됐다. 그때그때 상황에 따라 맞는 방법이 다르기 때문인데, 이런 분류 작업을 할 경우에 얼핏 생각하기에도 떠올릴 수 있는 방법은 다음과 같을 것이다.
* 제일 작은 숫자와 제일 큰 숫자를 기준으로 값으로 엔빵해서 분류하기
* 숫자의 갯수를 엔빵해서 동일한 갯수로 분류하기
첫번째 방법은 말이 좀 꼬여 있어서 그렇지, 이런 거다.
등간격으로 분류하기

이런 식으로 0~70까지로 범위를 잡고 숫자 값을 엔빵 쳐서 그룹을 나누고, 각 숫자들이 이런 그룹입니다~ 하고 나타낸 것. 엄청 흔하고 많이 쓰이는 방법이겠죠?
이럴 경우에 숫자 25는 Group 4 에 속하게 된다. 이러한 방법은 값 자체를 가지고 분류를 하는 것이므로, 평균(average)과 관계가 있다. 값 비율로 봐서는 얼추 맞는 그룹인 거 같은데... 뭔가 보기에, 숫자들이 좀 1~5그룹에 쏠려 있는 경향을 보이게 된다.
이유는 이 방법이 값 자체를 가지고 분류를 하는 것이므로, 평균(average)과 관계가 있기 때문.
만약에 마지막 숫자가 69가 아니라, 극단적으로 6900이라고 생각해보자. 그러면 0~7000 정도의 범위가 잡히게 되고 첫번째 그룹의 범위가 0~700, 두번째가 700~1400, ... 이런 식으로 나가게 되어 거의 대부분의 숫자가 Group 1 에 속하게 된다.
평균의 함정, 또는 통계의 왜곡 이라는 말을 많이 들어보셨을 텐데, 뭐 예를 들면 어느 직장 임직원의 평균 연봉이라든지... (사장 연봉이 100억이고 나머지 999명 직원의 연봉이 1000만원이라면 이 직장의 임직원 평균 연봉은 약 2억원)
이러한 평균의 왜곡을 방지하기 위해 두번째 방법은 갯수를 엔빵하는 것. 이 경우에는 숫자 갯수가 23개라 나누기가 좀 애매하지만 대략 2~3개로 나눈다고 생각해보자. 그러면 아래와 같이 된다.
같은 갯수로 분류하기

이번에는 양상이 많이 다르다! 숫자 25는 그룹을 2개나 오른쪽으로 이동해서, 이번에는 Group 6 에 속한다.
앞서 말했던 것과 같이 숫자가 굉장히 들쭉날쭉이라 평균을 쓰기가 힘들 경우에는 이런 분류 방법이 굉장히 효과적이다. 통계치로는 중간값 (median) 과 관계가 있다.
평균이 값 자체와 관계가 있다면 중간값은 단순히 전체 갯수가 10개라면 작은 거부터 나래비를 쭉 세워서 그냥 딱 5번째 있는 숫자를 고르는 것.
그래서 Natural Breaks는 왜 쓰는 거야?
아니 이렇게 효과적인 분류 방법들이 있는데, 그러면 이건 왜 쓰는 거야? 라고 했을 때...
구글에서 문헌을 이거저거 찾아봤는데, 이건 어떤 이론적인 근거라기보다는 단지 "시각화"라는 기준에서 봤을 때 사람의 눈이 가장 "자연스럽다" 라고 느끼는 분류 방법이 뭘까? 라는 질문에서 기인하는 듯 하다. 분명히 처음에 다른 사람들도 다 해 봤겠지. 근데 뭔가 이상한 거 같고, 왠지 이 시각화가 사실과는 다른 내용을 암시하는 듯 하고... 그래서 숫자들을 직관적으로 가장 잘 표현하기 위한 방법이 natural breaks다.
분류 결과부터 보면...

숫자를 자세히 보면, 뭔가 값이 "비슷비슷한" 애들끼리 뭉쳐있는 것 같은 느낌적인 느낌이 들죠?
그것은 정답. Natural Breaks는 그룹의 갯수를 딱 지정하면, 값이 비슷한 녀석들끼리 그룹을 만들어주는 알고리즘이다. 수학적으로 표현하면, 각각의 그룹 내의 분산은 최소화하고, 그룹 간의 분산은 최대화하는 작업을 수행해 준다.
아마 이러한 점이, 사람의 눈이 보기에 "자연스럽다" 라고 느끼는 점인 것 같다. 뭔가의 경계를 정하는 데 있어서 동질적인 것은 하나로 뭉치고 이질적인 것들 멀리 떨어뜨려 놓고 하는 점이? 사람도 데이터도 역시 유유상종인 것
그리고 이게 어디서 많이 본 거 같은 알고리즘인데... 라고 생각했었는데, 이 방식이 사실은 K-means clustering 알고리즘과 완전히 똑같은 방식이다. 단지 다른 것은 K-means clustering 은 차원에 무관하고 Natural breaks는 1차원 데이터를 쓴다는 점.

K-means clustering 도 데이터를 몇 개의 그룹으로 만들어주는 작업인데, 이것도 머... 다들 좋아하는 머신 러닝 방법 중에 하나이고 (비지도 학습), 굉장히 접근이 쉽고 (알고리즘 자체가 쉽다) 편의성에 비해 성능이 좋아서 (한마디로 가성비가 좋음) 유명한 알고리즘. 나중에 머신 러닝 주제로도 글을 좀 쓰려고 하는데 이건 그때 다루기로 하고... 지금은 그냥 데이터에 대해 분류할 갯수를 지정해 주면 이녀석이 알아서 뚝딱뚝딱 해서 데이터를 분류해 주는 거라고만 생각하자
어떻게 분류하는 것인지
이번에는 알고리즘이 동작하는 순서를 한 번 보자. 사실 안봐도 되는 부분이긴 한데 궁금하신 분들을 위해 남긴다. 우선 위키피디아에는 이렇게 쓰여 있다.
Jenks natural breaks optimization - Wikipedia
The Jenks optimization method, also called the Jenks natural breaks classification method, is a data clustering method designed to determine the best arrangement of values into different classes. This is done by seeking to minimize each class's average dev
en.wikipedia.org
중간 쯤에 보면
1. Calculate the sum of squared deviations from the class means (SDCM).
2. Calculate the sum of squared deviations from the array mean (SDAM).
3. After inspecting each SDCM, a decision is then made to move one unit from a class with a larger SDCM to an adjacent class with a lower SDCM.
이렇게 딱 3개 스텝으로 되어 있다고 하는데 이게 뭔소린가 하고 이해해 보려고 하다 때려치우고, 그냥 어차피 K-means clustering이랑 똑같은 거잖아? 그렇다면
1. 그룹의 갯수와 각 그룹의 중심값을 임의로 정함
2. 각 데이터 별로, 가장 가까운 중심값을 찾아 그룹을 할당
3. 할당된 결과를 가지고 그룹의 중심점을 재계산
4. 2-3을 반복
이런 식이다. 1번 스텝은 초기화를 해 주는 단계이고, 실제로는 2번과 3번을 계속 반복함으로써 위의 움짤처럼 그룹의 중심점이 계속 이동하면서 최적화 해주는 작업을 거치게 된다. 이를 코드로 한 번 살펴보자.
#-*- coding:utf-8 -*-
import numpy as np
# Step 1 : 그룹의 갯수를 정하고, 각 그룹의 중심 값을 정함
data = np.array([1, 2, 3, 5, 6, 9, 12, 14, 17, 18, 19, \
21, 22, 25, 29, 33, 34, 39, 42, 43, 55, 59, 69])
num_clst = 4
mxmn = [np.min(data), np.max(data)]
quan = (mxmn[1] - mxmn[0])/num_clst/2
# 클러스터의 갯수만큼 중심점을 만듬
clst_mu = np.array([quan*(2*i+1) + mxmn[0] for i in range(num_clst)])
print(f'각 클러스터별 평균 : {clst_mu}')
# Step 2 : 각 데이터에서 가장 가까운 그룹을 찾아서 그룹을 할당
# 데이터별 중심점과의 거리를 계산
diff = np.abs(data - clst_mu.reshape((num_clst,1))).T
# 그룹을 할당
clst = np.where(diff==diff.min(axis=1).reshape((len(data),1)))[1]
print(f'''* 데이터별 각 클러스터 중심점까지의 거리
{diff}\n\n* 클러스터 배당 결과\n{clst}''')
# Step 3 : 할당 결과를 가지고 그룹의 중심점을 재계산
print('* 클러스터별 데이터 현황')
for i in range(num_clst):
clst_mu[i] = np.mean(data[np.where(clst==i)[0]])
print(data[np.where(clst==i)[0]])
print(f'\n* 각 클러스터별 평균\n{clst_mu}')
# Step 4 : 2,3 스텝을 계속 반복
maxEpoch = 3
for epoch in range(maxEpoch):
diff = np.abs(data - clst_mu.reshape((num_clst,1))).T
clst = np.where(diff==diff.min(axis=1).reshape((len(data),1)))[1]
print(f'- {epoch}th loop -\n\n* 클러스터별 데이터 현황')
for i in range(num_clst):
clst_mu[i] = np.mean(data[np.where(clst==i)[0]])
print(data[np.where(clst==i)[0]])
print(f'''\n* 각 클러스터 평균\n{clst_mu}\n
* 데이터별 각 클러스터 중심점까지의 거리\n{diff}\n
* 클러스터 배당 결과\n{clst}\n\n''')
데이터는 첫 그림의 것을 그대로 썼고, 코드를 돌리다 보면 알아서 데이터가 착착 할당이 된다. 이 알고리즘에서 중요한 것은 그룹별 중심점의 초기값을 제대로 잡는 것. 근데 이런 식으로 학습을 시켜가는 알고리즘은 뭐든 초기값을 제대로 잡는 게 중요하니까 사실 이것만 그런 것도 아니다.
이렇게 직접 날코딩을 할 필요는 사실 없고, QGIS에서 옵션으로 딱 선택을 하면 바로 적용이 가능하다.

누가 요즘에 무식하게 날코딩으로 다 하겠니... 남들 해놓은 거 갖다 쓰는 거지 뭐 ㅋㅋ
알고리즘을 이해하기 위해 저 코드도 한번 짜 보실 분은 한번 짜 보면 되고, 그렇지 않으면 뭐.. 그냥 갖다 쓰자. (솔직히 파이썬으로 짤 때도 jenkspy 라는 모듈을 쓰면 한줄이면 된다.)
import pandas as pd
import jenkspy
# 일단 데이터 대충 정의하고
sales = {
'val': [1, 2, 3, 5, 6, 9, 12, 14, 17, 18, 19, 21, \
22, 25, 29, 33, 34, 39, 42, 43, 55, 59, 69]
}
df = pd.DataFrame(sales)
df.sort_values(by='val')
# 그럼 이제 내추럴 브레이크를 jenkspy가 어떻게 만들어주는지 볼까? (2개로 분류)
breaks = jenkspy.jenks_breaks(df['val'], nb_class=10)
print(breaks)
df['cut_jenks'] = pd.cut(df['val'],
bins=breaks,
labels=['bucket_0', 'bucket_1', 'bucket_2', 'bucket_3',\
'bucket_4', 'bucket_5', 'bucket_6', 'bucket_7',\
'bucket_8', 'bucket_9'],
include_lowest=True)
df.sort_values('val')
이렇게 하면 끝. 날코딩은 무슨... ㅋㅋㅋ 어쨌든 방식을 이해하자는 면에서 코드도 한번 짜보고, 결과도 보고 했다.
Natural Breaks 라는 방식이 어떤 통계적인 의미를 가지는 것이 아니라 사람이 직관적으로 보기 좋은 식으로 분류를 해 주다 보니, 데이터가 완전히 완성되어 있으면 그냥 시각화를 해 주면 땡인데 그렇지 않고 데이터가 더 추가된다든지 하면 결과를 조금... 오히려 왜곡된 해석을 불러 일으킬 소지도 있다고 한다. 경우에 따라서 맞는 방식으로 시각화하는 것이 중요한 듯.
이렇게 공간 정보에 대한 글의 한 꼭지를 마치고, 여기서 Natural Breaks를 소개한 김에 다음부터는 머신 러닝 관련해서도 좀 글을 써 봐야겠다는 다짐과 함께 이 글을 마칩니다.




댓글