오늘 알아볼 것은 클러스터링 기법 중에 계층 (Hierarchy) 을 이용해서 군집화를 수행하는 계층적 클러스터링입니다. 영어로는 Hierarchical Clustering이라고 해요.

데이터 간의 관계
클러스터링을 말하기에 앞서, 데이터 간의 관계에 대해 지난 글에서 이야기한 점을 다시 한 번 짚고 넘어가겠습니다. 지난 글에서 이야기한 내용을 요약하자면 다음과 같습니다.
1. 위 8개의 데이터는 직관적으로 4개씩 묶을 수 있는 것처럼 보인다.
2. 그 근거는, 데이터 상호 간의 "거리"를 관계로 규정하고, 관계성이 높은 것끼리 묶은 것이다.
이렇게 우리가 머리 속으로 직관적으로 할 수 있는 클러스터링을 기계가 했던 것이 k-means clustering이라고도 말씀드렸어요. 관련 글은 아래와 같습니다.
데이터 분류 (클러스터링) 기법 : K-means clustering
데이터 분류 (클러스터링) 기법이 뭐가 엄청 많은데, 이제부터 하나씩 공부해 가면서 정리 겸 블로그에 남기려고 합니다. 그 첫번째로 가장 기초적이고 가장 쉬운 K-means clustering부터 시작해 볼께
guzene.tistory.com
데이터 간의 관계는 "거리" 또는 "유사도" 로 정의할 수 있습니다. 여기에서는 유클리드 거리로 정의를 하고 진행할께요.
k-means clustering과 같은 건가요?
클러스터링은 데이터 간의 관계를 확인하고 너네랑 너네 같은 편 해 하고 묶어주는 건데, 이 방식이 다릅니다.
k-means clustering은 사전에 대충 먼저 그룹핑을 해 놓고 시작을 하는 반면에, 계층적 클러스터링은 데이터끼리 관계를 일일이 싹 다 확인합니다. 이제부터 한번 이야기해 볼께요!
Step 1 : 전체 데이터 간의 관계를 보고 묶어 보자
데이터 간의 관계라고 얘기는 했지만, 이게 뭐 사실은 데이터들 각각의 거리를 얘기하는 거예요. 그렇다면.... 싹 다 계산해 버리면 되잖아요?

이렇게 4개의 데이터가 있다고 하겠습니다. 마찬가지로 두개씩 묶으면 돼 보이죠? 계층적 클러스터링에서는 이렇게 합니다.
일단 4개의 데이터는 아래와 같습니다. 그 각각의 데이터에 대해서 각각의 거리를 계산합니다.

데이터 1과 2가 거리가 가장 가깝습니다. 즉 관계가 제일 높죠? 그러면 이 두개를 묶습니다. 이제 너네는 한 그룹이야 하고요.
그러고 나면 다시 거리를 계산합니다. 어떻게? 데이터1과 2를 하나의 그룹으로 보고 계산을 하는 거죠. 그러면 그룹과 하나의 데이터 간, 또는 더욱 묶이게 되면 그룹과 그룹 간의 거리 계산 방법이 나와야 할 텐데, 크게 네가지 정도가 있는 것 같습니다.
참고. 그룹 간의 거리 계산

위에서 보이는 것처럼 4가지 방법이 있습니다.
1. 최소 거리 : 각 그룹별로 가장 가까운 점들끼리 거리를 계산
2. 최대 거리 : 각 그룹별로 가장 멀리 있는 점들끼리의 거리를 계산
3. 그룹 무게중심과의 거리 : 각 그룹들의 무게중심을 구해서, 그들 간의 거리를 계산
4. 전체 거리 평균 : 각 그룹에 속한 모든 데이터끼리의 거리를 계산한 값을 평균
뭘 써야 하나요?
계층적 클러스터링을 제공하고 있는 scipy 패키지에서의 공식 문서 예제는 최소 거리를 사용하고 있습니다. 저는 이 글에서 평균 거리를 사용했습니다.
이렇게 하면 아마... 데이터의 차원이 너무 크거나 갯수가 너무 많아진다면 계산 코스트가 엄청 올라가겠죠? 일단은 샘플 식으로 예제를 수행했기 때문에 전체 데이터에 대해 계산을 거리하는 방식으로 진행했어요!
Step 2 : 묶인 그룹을 포함하여 전체 데이터 간의 거리를 재계산을 반복
이건 그림으로 보는 게 빠를 거 같아요.

위의 거리 계산은 모든 점들 간의 거리를 계산하여 평균하는 방식을 사용했습니다. 어쨌든, 그 다음으로는 데이터 3과 데이터 4가 묶이게 되겠네요. 그걸 묶고 또 계산해볼까요?

오! 이제 데이터 1,2와 데이터 3,4가 가장 가까우니까 이 둘을 또 묶으면 되...
아?

뭐야 다 묶이잖아!!
... 네 맞습니다. "끝까지" 거리 계산을 수행하면 모든 데이터가 하나로 다 묶이죠... 그래서 핵심은 적당한 수준에서 끊는 겁니다.
덴드로그램 (Dendrogram)

위 그래프를 보겠습니다. 원 데이터는 오른쪽 그래프를 참조하시구요. 보시면, 데이터가 가까운 것부터 묶여 나가는 것을 보실 수가 있어요. 세로축의 거리를 보시면 이해하실 수 있을 거예요.
그래서 만약에 내가 2개의 클러스터로 나누고 싶다! 라고 하면 저기 중간쯤에서 딱 그만두는 겁니다. 그러면 오른쪽의 그래프와 같이 분류가 되겠죠? 이게 끝이예요! 만약에 데이터가 많다라고 하면.... 아래 그림처럼 될겁니다.

코드로 알아보자
이제부터 저 위의 덴드로그램을 그리고 클러스터링한 결과를, 실제 코드로 한 번 살펴보겠습니다.
#-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage, cut_tree
# 데이터 만들기
num_data = 1
dimension = 2
data = np.random.randn(num_data, dimension)
offsets = np.array([[5,2], [-1,5], [2,3], [5,5], [-4,0], [4,-3],[6,8]])
for offset in offsets:
data = np.append(data,np.random.randn(num_data, dimension)*1.2 + offset, axis=0)
# 플랏
fig = plt.figure(figsize=[4,4])
plt.scatter(data.T[0],data.T[1], s=100)
plt.grid()
plt.show()
# 클러스터링하기
links = linkage(data, 'average')
# 덴드로그램 그리기
plt.figure(figsize=(12,12))
dendrogram(links, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.show()
# 클러스터 결과 시각화
num_cluster = 6
cluster = cut_tree(links, num_cluster).reshape(len(data)) # 데이터별 클러스터 반환
clustered = []
for i in range(num_cluster):
clustered.append(data[np.where(cluster==i)[0]])
fig = plt.figure(figsize=[10,10])
for clustered_data in clustered:
plt.scatter(clustered_data.T[0],clustered_data.T[1], s=6)
plt.grid()
plt.show()위 코드는 아래 파일로 올려두었습니다.
코드 자체에 주석을 살짝(?) 달아두었으니, 한 번 따라가 보시구요. 실제로 클러스터링 된 결과를 한 번 보겠습니다.

위 코드로 임의로 생성한 데이터에 대해 클러스터링을 수행한 결과이구요, 보시다시피 클러스터의 갯수는 3개입니다.
음... 뭐... 잘 되는 건가?
k-means clustering과의 비교
위의 의문을 해결하기 위해 글 첫머리에 언급했던, 동일하게 거리 기반으로 클러스터링을 수행하는 k-means와 비교해 보도록 하겠습니다. 똑같은 데이터로 3개의 데이터로 구분한 결과인데요, 다음과 같습니다.

위의 결과를 비교해 보면, 계층적 클러스터링이 훨씬 더 자연스러운 결과를 보여주는 것을 확인할 수 있습니다.
그도 그럴 것이, k-means clustering 은 미리 분류를 대충 해 두고, 데이터와 클러스터 중심점과의 거리만을 비교해서 분류하다보니 저렇게 구분이 힘든 데이터에서는 딱 3등분하는 식으로 될 수밖에 없을 것으로 보입니다.
계층적 클러스터링은 그와 달리 모든 데이터를 비교해가면서 분류하다 보니까 최대한 자연스럽게 구분이 되는 것 같아요. 좀 더 극단적인 예를 아래와 같이 한 번 보겠습니다.

이 결과에서, 사실 k-means clustering은... 분류라고 보기는 힘들죠? 그냥 반띵해 둔 거 같잖아요? 근데 계층적 클러스터링은 어떻게 한 번 해보려고 하는 게 느껴집니다. 이렇게 하기 위한 문제는 계산 비용이 많이 든다는 것 같습니다.
클러스터 갯수를 달리한 결과를 몇 개 한번 볼게요
클러스터 4개

클러스터 6개

클러스터 10개

전반적으로 계층적 클러스터링의 결과가 훨씬 양질의 것으로 보입니다.
마지막에 10개 클러스터의 경우에는, 8개밖에 없는 거 아냐? 라고 할 수 있는데 엄청 적은 데이터가 속한 클러스터가 숨어 있어요.
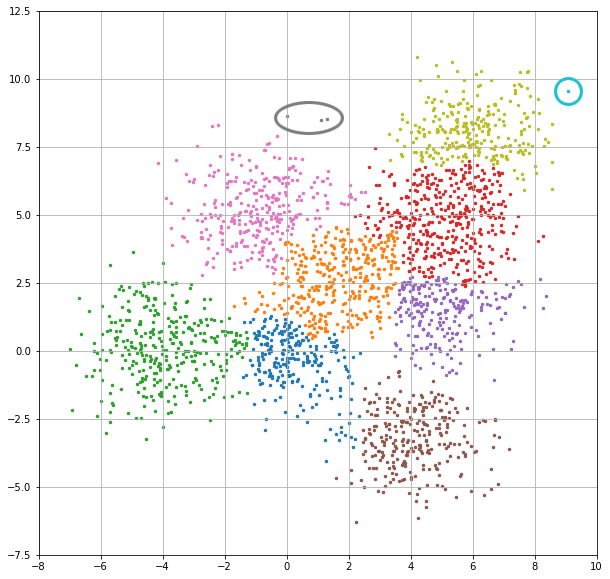
저는 어거지로 분류하는 것보다는 이게 훨씬 나아 보이네요. 저정도의 데이터라면... 인근 클러스터로 편입해버려도 될 거 같고, 여러 처리하는 방식이 있을 것으로 생각이 됩니다.
오늘은 계층적 클러스터링 (Hierarchical Clustering) 에 대해 알아봤습니다. 거리 또는 유사도 기반의 분류 알고리즘이고, 그와 유사한 k-means clustering과의 비교를 통해 차이점도 살펴봤어요.
다음에는 "랜덤 포레스트" 에 대한 글로 돌아오겠습니다. 긴 글 읽어주셔서 감사하구요, 다음에는 더 알찬 글로 찾아오겠습니다!




댓글