지난 시간에 이어서 QGIS를 이용한 시각화를 좀 더 들여다보자.
지난 글
공간 데이터의 이해 - QGIS를 써 보자
공간이란 무엇일까? 보통 3차원 공간이라는 얘기를 많이 하는걸로 봐서는, 우리가 딛는 땅, 하늘, 그리고 지하 이런 것들을 모두 공간이라고 하는 것일 테고, 그러면 공간 데이터라는 건, 공간에
guzene.tistory.com
지난 시간에는 시각화보다는 QGIS가 뭔지, 어떻게 쓰는 건지에 좀 더 초점을 맞춰서 글을 진행했었고, 이번 시간에는 이걸 활용한 무언가에 좀 더 초점을 맞춰서 얘기하려고 한다.

지난 시간에는 전국 데이터를 불러와서 QGIS를 이용해서 지도랑 매칭해보고, 간단히 데이터가 어디있는지를 봤었다. 이번에는 조금 더 자세하게 보기 위해 서울시 데이터만 따로 쪼개고, 서울시 데이터에 추가적인 데이터를 붙여서 알록달록한 그림을 그려보려고 한다.
서울시 데이터만 분리하자
지금 이 글은 파이썬을 이용한 프로그래밍 지식이 약간은 있다고 가정하고 쓴다.
대한민국 최신 행정구역(SHP) 다운로드 – GIS Developer
www.gisdeveloper.co.kr
지난 시간에 위 사이트에서 행정구역 shp 파일을 모두 다운 받고 QGIS에 얹어봤다. 없으면 다운받고, 지난 글을 참조해서 QGIS에 데이터를 올려보자.
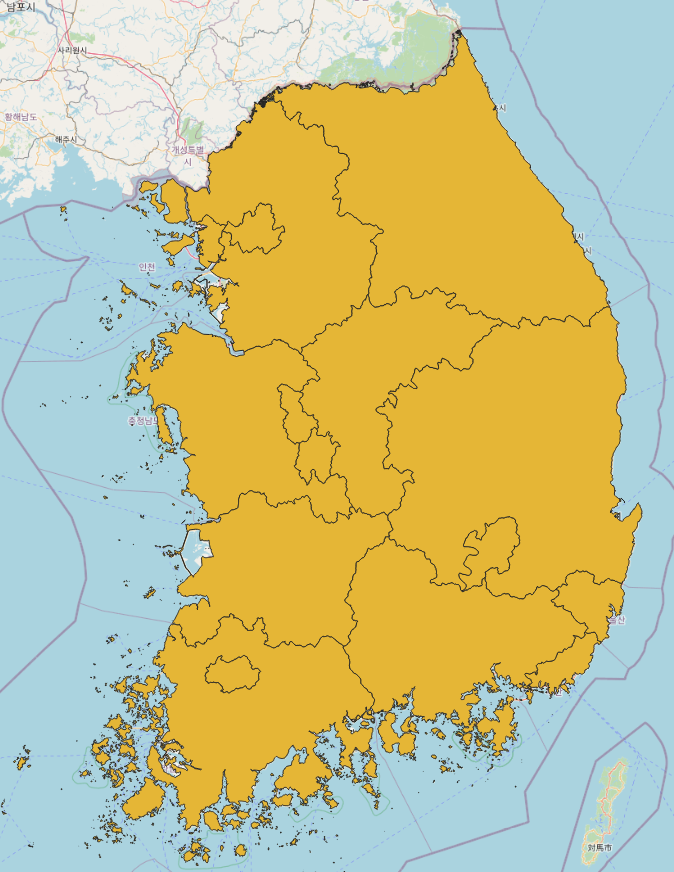
CTPRVN 데이터를 얹게 되면 이런 식으로 시/도 경계가 나타난다. 여기서 어떻게 서울시만 골라낼 수 있을까?
QGIS 내에서 할 수 있는지는 모르겠는데, 내가 한 것은 아래와 같다.

데이터를 CSV로 저장
순서대로 따라가보자. 먼저 올려진 데이터를 csv로 저장하기 위해서 아래와 같이 메뉴를 선택한다.
그러면 아래와 같은 팝업이 뜬다.
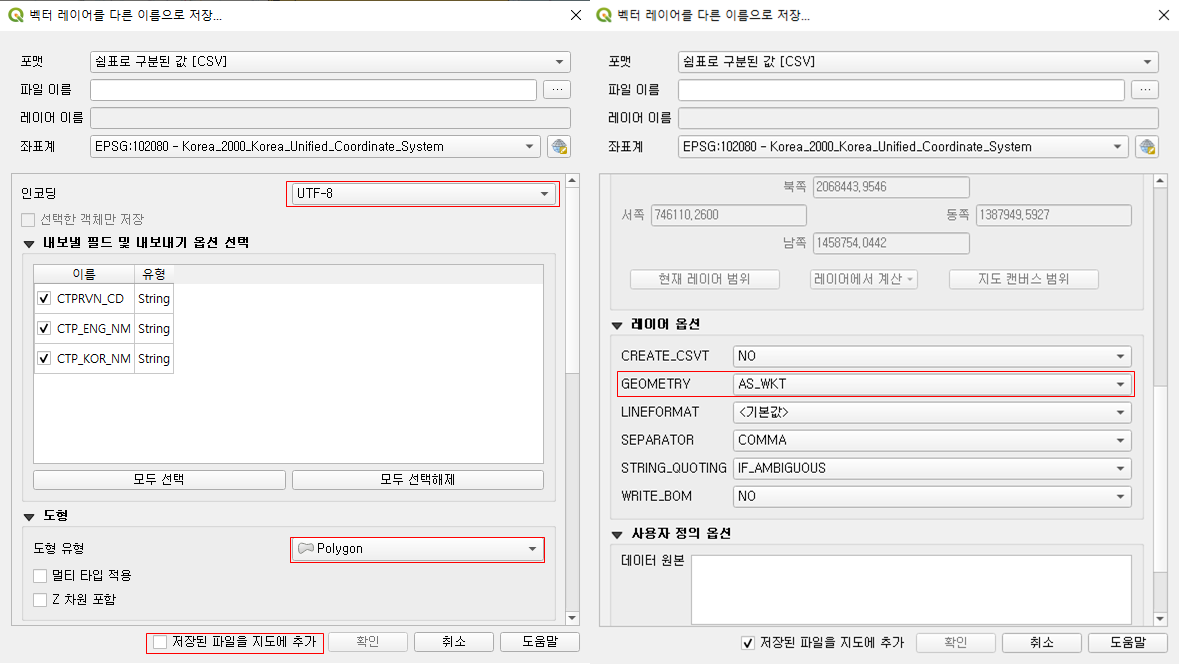
* 경로명은 본인의 컴퓨터에 맞게 알아서 작성.
* "저장된 파일을 지도에 추가" 옵션 체크 해제
* 인코딩을 "UTF-8" 로 변경 (그편이 다루기가 쉽다)
* 도형 유형 : 폴리곤으로 설정
* 레이어 옵션 : AS_WKT
요정도 사항에 주의해서 csv로 별도로 저장해주자. 레이어 옵션의 WKT는 Well Known Text 의 약자인데, 도형의 경계좌표를 표현하는 방식이라고 생각하면 된다. 지정해주지 않으면 기본값은 도형의 모양을 폐기해버리므로, 꼭 지정해주자.
저장하고 나면 대략 파일 크기가 26MB 정도 된다. 절대... 까진 아니지만 엑셀로 이 csv를 열어보겠다...라는 당찬 꿈은 잠시 접어두자. 팔로팔로미
파이썬으로 서울시 데이터만 골라내자
이 글을 보는 여러분들이 파이썬 에디터로 뭘 쓰는지는 모르겠지만, 저는 주피터 노트북 기준으로 진행합니다. 보시는 분들이 지금 반말 존댓말 막 섞여 있어서 혼선을 가지실 수도 있는데 뭔가 독자들에게 직접적인 얘기를 전달할 때는 존댓말이고, 혼자서 얘기할 때는 반말로 얘기해요. 이상한가? 전부 존댓말로 할까요??
이야기가 좀 딴데로 샜는데, 한번 일단 불러와보자
#-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
filePath = 'D:/GIS/shp_csv/'
df_ctprvn = pd.read_csv(filePath + 'exported/shp_CTPRVN.csv', encoding='utf-8')
df_ctprvn.head()여기까지 짜고 pandas 데이터프레임을 출력해보면 아래의 형태를 띈다.
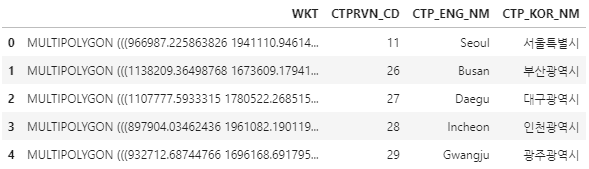
말한 것처럼 폴리곤을 정의하는 WKT가 들어가 있고, 그다음은 코드, 영어명, 한글명 순이다.
여기에서 제일 중요한 게 코드이다. 읍/면/동까지 모든 데이터를 들여다보면, 우리나라 지역코드는 아래와 같이 8자리로 이루어져 있다.

위와 같은 식이다. 코드가 11110101이면, 서울시 종로구에 있는 청운동을 뜻한다. "시"라는 단위가 두군데에 있어서 헷갈릴 수 있는데, 시/도 자리의 시는 특별시/광역시/특별자치시/특별자치도 만을 의미한다. (현재 우리나라의 특별자치시는 세종, 특별자치도는 제주)
우리나라 행정 구역에 대한 설명이었고, 쨌든 본론으로 돌아오면 지금 우리가 뽑으려는 데이터는 "서울시" 이고, 그렇다는 건 지역코드의 맨 앞자리 2개가 11인 것만 뽑아서 csv로 다시 저장해주면 끝!
위의 코드에 이어서 아래와 같이 작성한 후에, 두 개를 붙여서 실행시켜 보자.
# 코드 및 명칭 정보 별도 리스트로 작성
ctprvn_cd = np.array(df_ctprvn['CTPRVN_CD']).tolist()
ctp_nm = np.array(df_ctprvn['CTP_ENG_NM']).tolist()
# 시도별로 파일로 각각 내보내기
for i in range(len(df_ctprvn)):
df_ctprvn.iloc[[i],:].to_csv(filePath + 'shp_' + ctp_nm[i] + '_CTPRVN.csv')이렇게 하고 나면, 시/도별로 파일이 별도로 쭉쭉 저장된다. 코드는 아래를 클릭해서 다운받자.
그러면 시/도는 했고... 시/군/구랑 읍/면/동도 다 해야 하는 거 아닌가?
맞다. 하지만 원리는 알았으니까, 이제 한꺼번에 코드를 봐도 이해하는 데 큰 무리는 없을 것이다. 아래를 보자.
#########################################
# 시/군/구 SHP를 시/도별로 분리
#
df_sig = pd.read_csv(filePath + 'exported/shp_SIG.csv', encoding='utf-8') # 불러오기
df_sig['CTPRVN_CD'] = (df_sig['SIG_CD']/1000).astype(np.int64) # 시/도별 코드 추가
df_sig = pd.merge(df_sig, df_ctprvn[['CTPRVN_CD', 'CTP_ENG_NM','CTP_KOR_NM']], how = 'left')
# 시도별로 파일로 각각 내보내기
for i in range(len(df_ctprvn)):
df_sig.loc[df_sig['CTPRVN_CD']==ctprvn_cd[i],:].to_csv(filePath + 'shp_' + ctp_nm[i] + '_SIG.csv')
#########################################
# 읍/면/동 SHP를 시/도별로 분리
#
df_emd = pd.read_csv(filePath + 'exported/shp_EMD.csv', encoding='utf-8')
df_emd['SIG_CD'] = (df_emd['EMD_CD']/1000).astype(np.int64) # 시군구별 코드 추가
df_emd = pd.merge(df_emd, df_sig[['SIG_CD', 'SIG_ENG_NM','SIG_KOR_NM']], how = 'left')
df_emd['CTPRVN_CD'] = (df_emd['EMD_CD']/1000000).astype(np.int64) # 시/도별 코드 추가
df_emd = pd.merge(df_emd, df_ctprvn[['CTPRVN_CD', 'CTP_ENG_NM','CTP_KOR_NM']], how = 'left')
df_emd.head()
# 시도별로 파일로 각각 내보내기
for i in range(len(df_ctprvn)):
df_emd.loc[df_emd['CTPRVN_CD']==ctprvn_cd[i],:].to_csv(filePath + 'shp_' + ctp_nm[i] + '_EMD.csv')위의 코드는 물론 저 위쪽 코드에 이어서 모두 작성해야 한다. 시/군/구 정보나 읍/면/동 정보도 전부 시/도별로 분리하려는 것이라 위의 정보를 참조한다.
말이 좀 헷갈릴 수 있는데, 전국의 "구" 중에서 서울특별시의 구만을 떼어내서 저장하고, 부산광역시의 구를 떼어내서 저장하고... 이런 식으로 실행해주는 코드다. 잘 뜯어보자. 전체 코드는 아래에 있다. 귀찮으면 그냥 경로 정도만 바꿔서 돌리자.
CSV를 QGIS로 불러오자
2단계 / 3단계를 파이썬에서 한꺼번에 마쳤다. 이제 QGIS에서 다시 불러와보자.
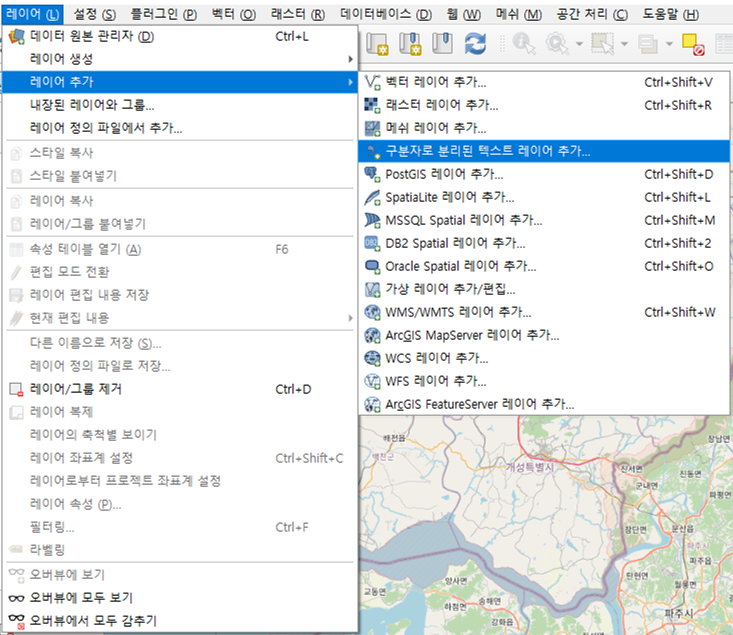
메뉴에서 위처럼 선택하면 팝업창이 뜬다.
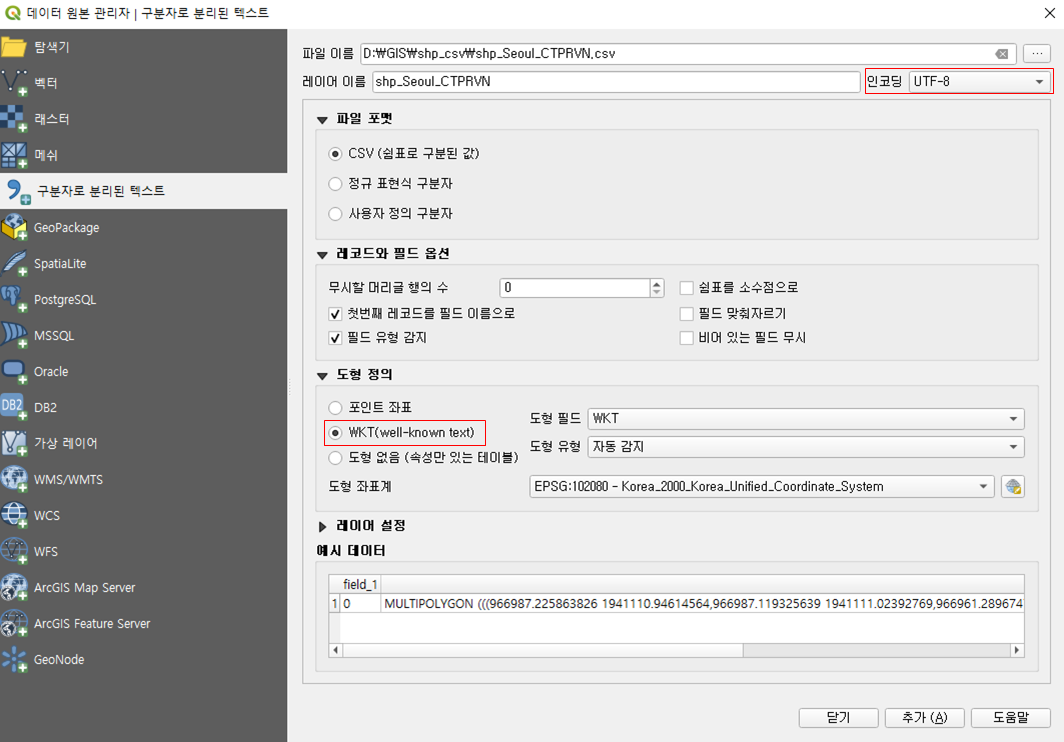
시/도 데이터를 먼저 불러와 보자. 주의할 것은 2가지. 도형의 타입을 WKT로 선택하고, 인코딩은 아까 우리가 UTF-8로 내보내서 작업했기 때문에, 동일하게 UTF-8로 불러들인다.
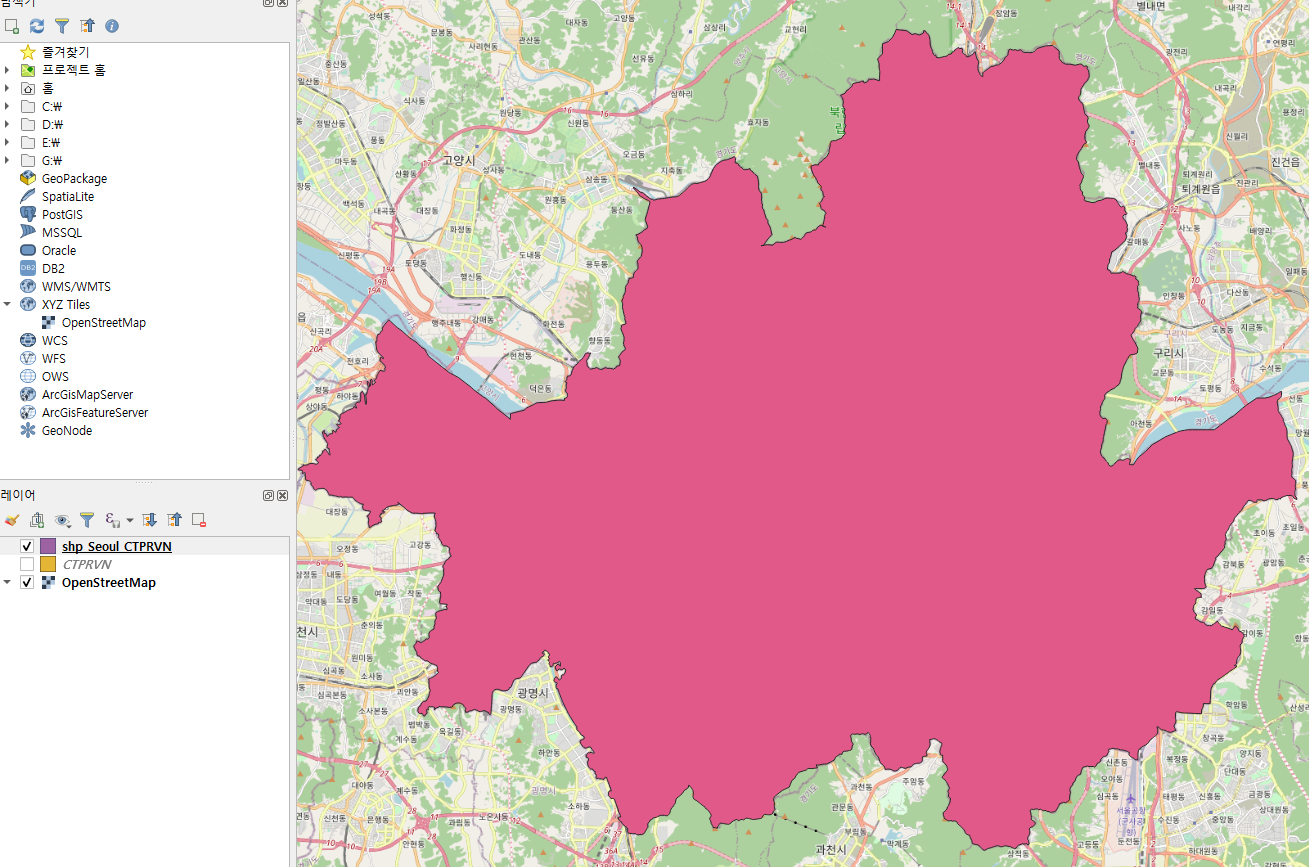
오... 제대로 됐어! 이제 지난 시간에 배운 걸 활용해서 몇가지를 해보자.
* 색깔을 투명하게 하기
* 선을 두껍게 하기
* 선 색상 변경하기
이건 설명하지 않겠다. 지난 글을 보고 따라서, 또는 응용해서 해보자.
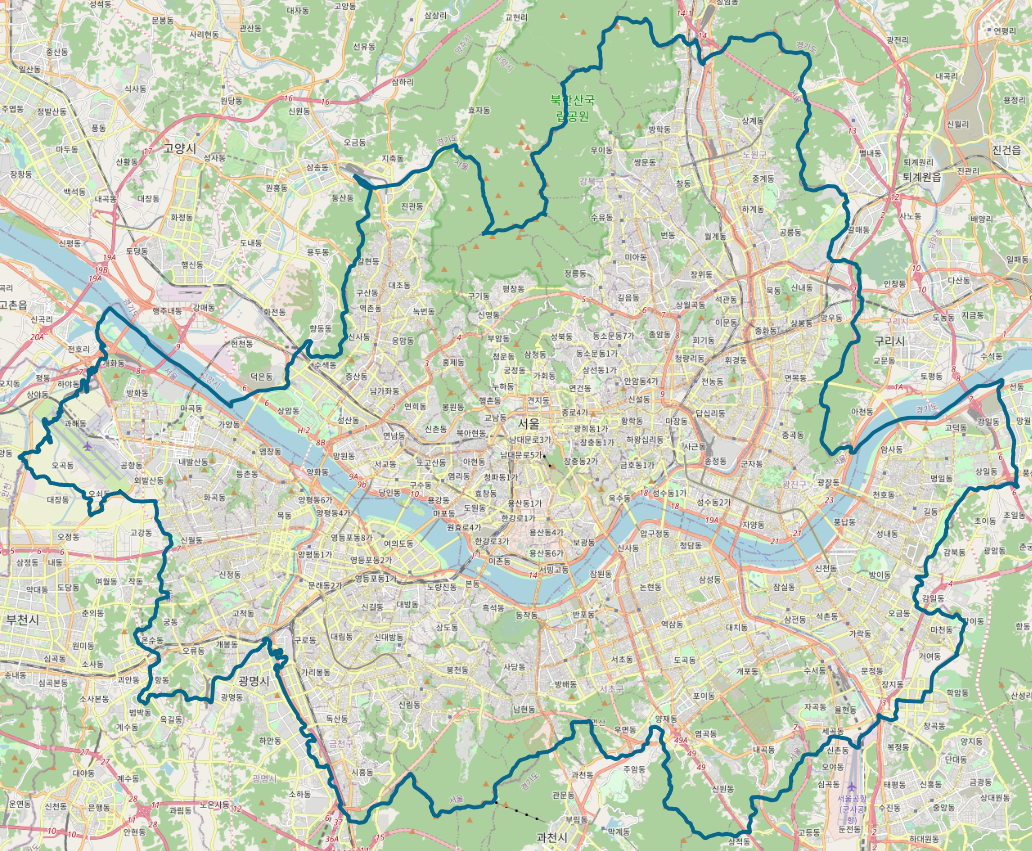
이제 시/군/구 데이터 (SIG) 와 읍/면/동 데이터 (EMD) 를 차례차례 불러와서 아래와 같이 세팅해보자.
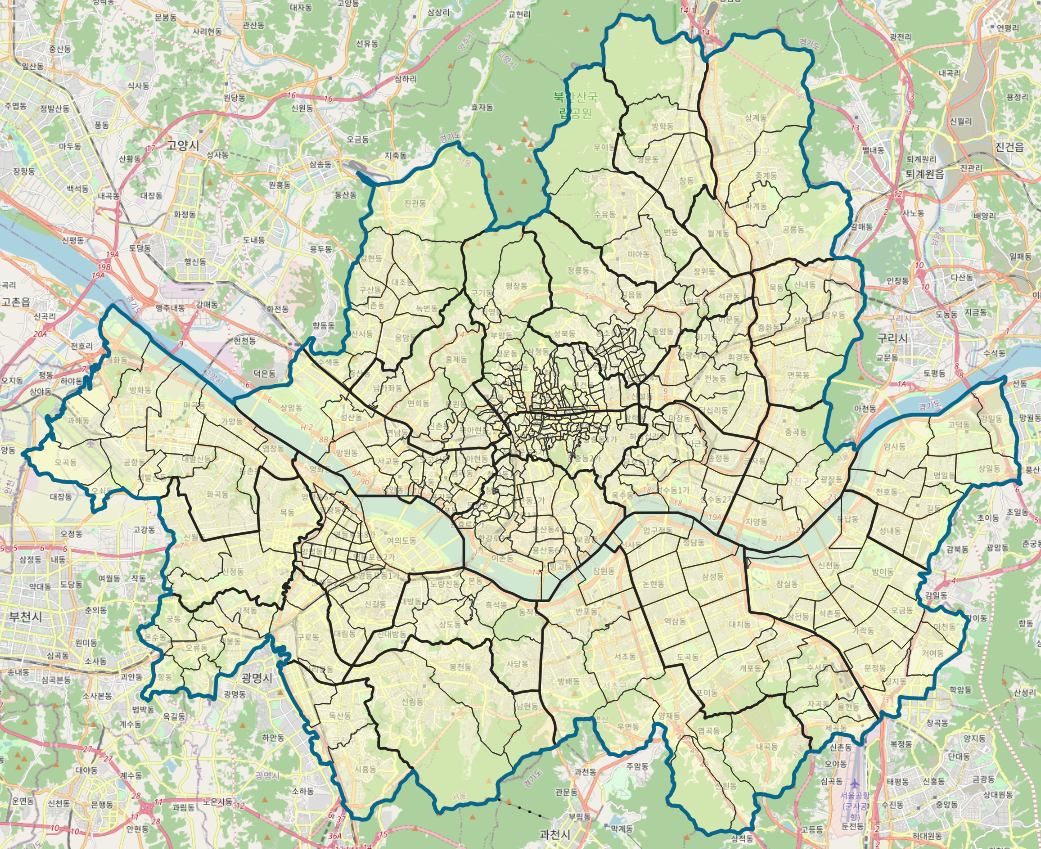
* 시/군/구 데이터도 색을 투명하게 하고 경계선을 약간 두껍게 했다.
* 읍/면/동 데이터는 색을 반쯤 투명하게 하고 경계선은 그대로 두었다.
아니 뭐 사실 여기까지 했다고 해서 뭐 한 건 아니고 그냥 셋업만 한 수준이지만, 벌써 뭔가 그럴싸하다. 하지만 뭐 이건 그냥 껍데기니까, 데이터를 한번 얹어보자.
데이터 추가와 연결
"서울 열린 데이터 광장" 에 들어가면, 서울시가 공공에 공개하는 각종 데이터를 다운받을 수 있다. 이 중에 하나를 다운받아서 데이터를 추가하고 각 동과 연결해보자.
서울 열린데이터광장
전체 6,694건 을 찾았습니다. 정확도순 최신공개일순 조회순 제목순 조회 공공데이터 [문화/관광] 서울시 시설대관 공공서비스예약 정보 서울시 및 산하기관, 자치구의 시설대관 예약정보를 제�
data.seoul.go.kr
홈페이지에 들어가서, "법정동" 으로 검색하면 뭐가 줄줄이 나오는데, 그 중에 제일 위에꺼를 클릭해서 들어가보자.
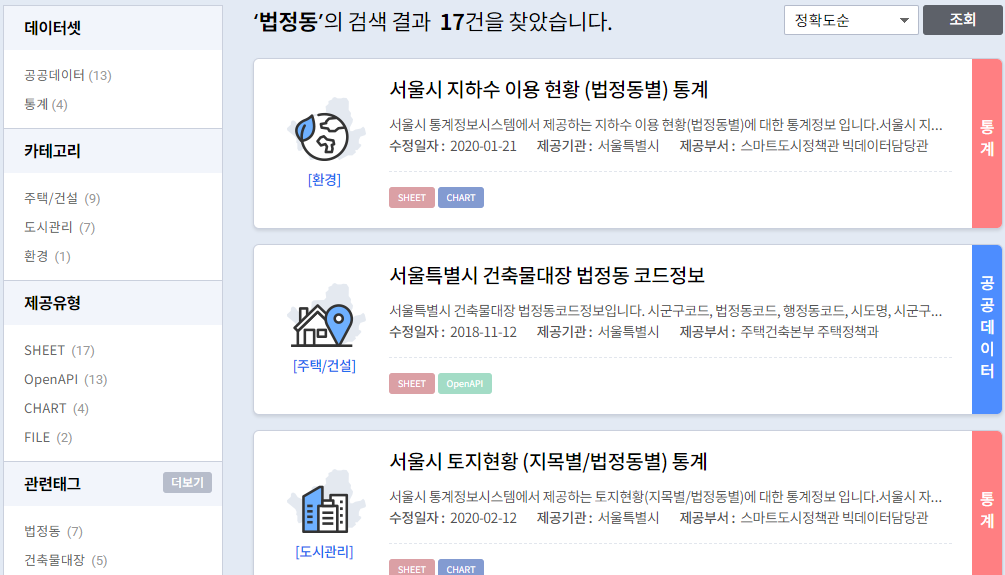
왜 하필 저거냐고? 사실 이유는 이렇다.
우리나라 "동"의 체계는 법정동/행정동 2가지로 구분된다. 법정동은 법적 업무 (지적 업무 등) 의 기준이 되고, 행정동은 행정 편의상 나눠둔 이름이다. 법정동은 잘 바뀌지 않지만, 행정동은 자주 바뀐다. 상세한 건 아래 기사를 참조하자.
'한 동네, 두 이름'…헷갈리는 행정동·법정동 | 연합뉴스
'한 동네, 두 이름'…헷갈리는 행정동·법정동, 김광호기자, 정치뉴스 (송고시간 2018-05-22 07:43)
www.yna.co.kr
그래서 뭐?
열린데이터 광장에서 제공하는 데이터 (또는 통계) 의 대다수가 "행정동"을 기준으로 작성되어 있다. 그런데 우리가 불러온 동의 경계 파일은 법정동을 기준으로 만들어져 있다. 그래서 매칭이 안된다.
...뭐라고?
진..진정하자... 매칭하는 건 다음 시간으로 미뤄놓고, 그래서 일단은 법정동 기준으로 제공하는 데이터를 찾기 위해서 검색을 했고, 나온 게 지하수 이용 현황 데이터 (...) 정도다. 지하수 이용 현황 같은 거 알아봐야 별 재미도 없긴 하지만 일단은 이 데이터를 다운받아보자.
쉼표가 많아서 csv로 제공하기가 곤란하고 어쩌구저쩌구... 하니까, 일단은 내가 다음어둔 아래 파일을 이용하자.
마찬가지로 쉼표로 구분된 레이어를 추가해 보자.
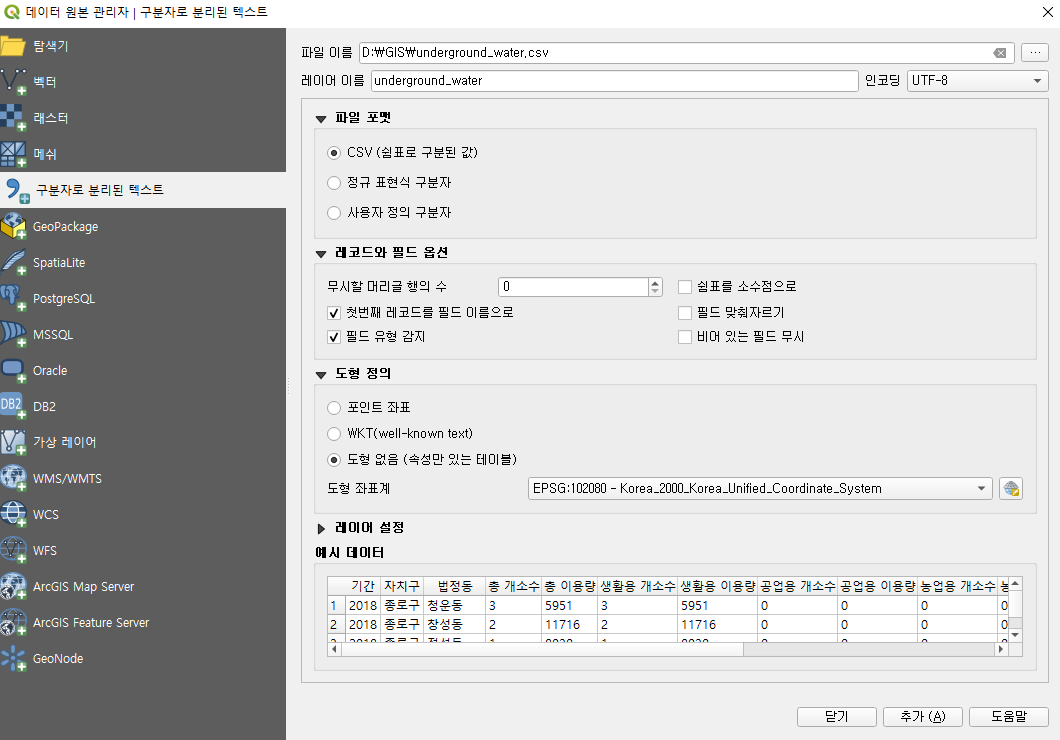
이번에는 데이터만 담겨있고 공간의 모양이 없는 데이터이므로 도형 없음 옵션을 선택해서 불러오자. 그러면 아래와 같이 레이어가 추가되는데, 겉보기에는 아무런 변화가 없게 된다.
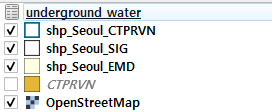
왜냐면 이녀석은 그냥 따로 노는 데이터일 뿐이기 때문... 이제 이거랑 실제 공간 데이터를 연결해보자.
자치구와 법정동을 하나의 데이터로 만들자
이 작업을 통해 하나의 유일한 지역 이름을 만들어보자. 그리고 나서 그걸 키(key)로 해서 두 데이터를 연결할 것이다.
지하수 정보의 속성 창을 열어서, 원본 필드 탭으로 들어간다.
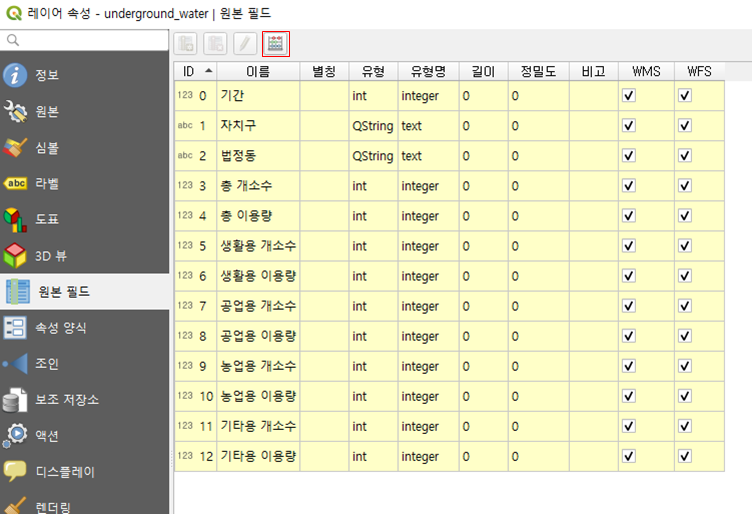
위쪽의 주판같이 생긴 아이콘을 클릭하자. 그러면, 아래처럼 새로운 필드 (엑셀로 치면 새로운 열) 를 추가할 수 있다.
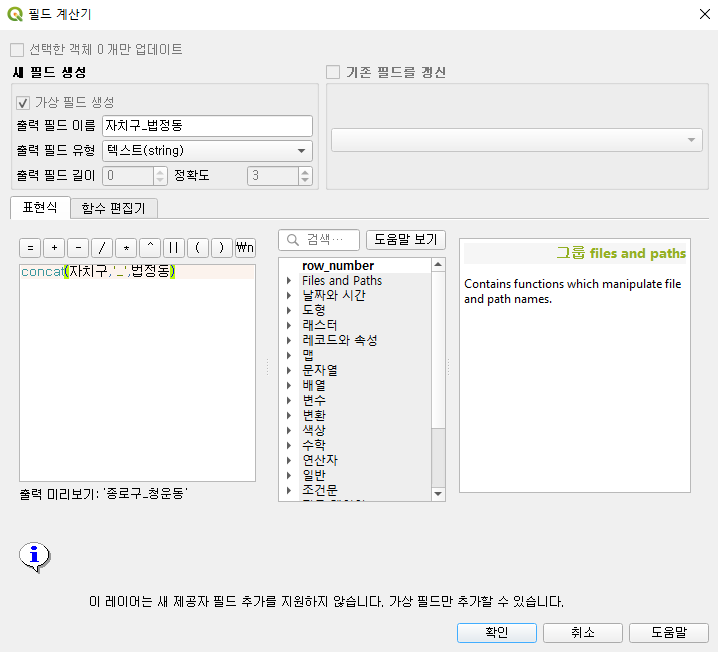
concat은 문자열을 하나로 합쳐주는 함수다. 즉, 저렇게 입력하게 되면 각 자치구의 이름과 법정동의 이름을 지정한 형식으로 합쳐준다. 출력 필드 유형을 "텍스트(string)" 으로 바꿔주는 것에 유의하자!!! 데이터 형태가 잘못되면 다 망한다. 확인을 누르면 끝.
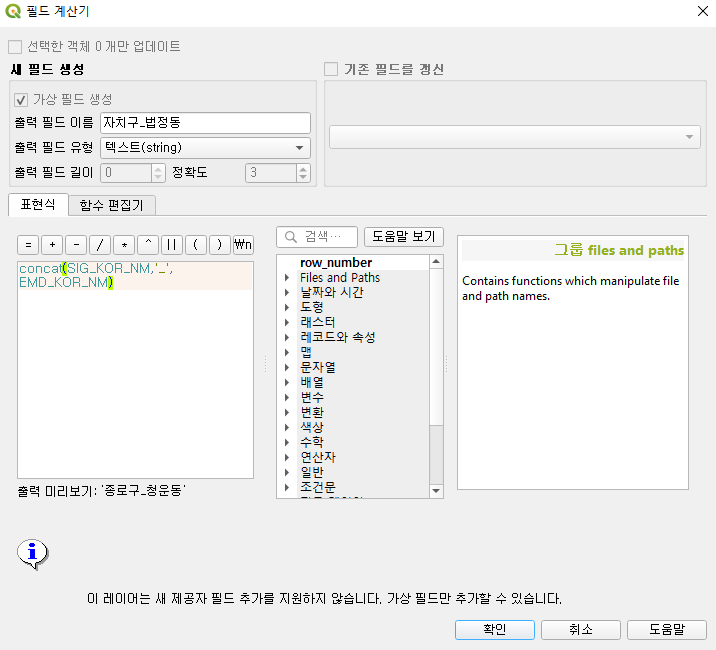
shp_Seoul_EMD 레이어에도 동일한 작업을 해 준다. 그러면 이제 이 유일한 동 이름을 가지고 두 데이터를 연결할 수 있게 됐다. 사실 이따위로 귀찮은 작업은 잘 안하는데 (파이썬으로 미리 데이터를 만들고 QGIS로는 보기만 하는 편) 일단 설명이니까 전부 다 해보자.
데이터를 연결하자
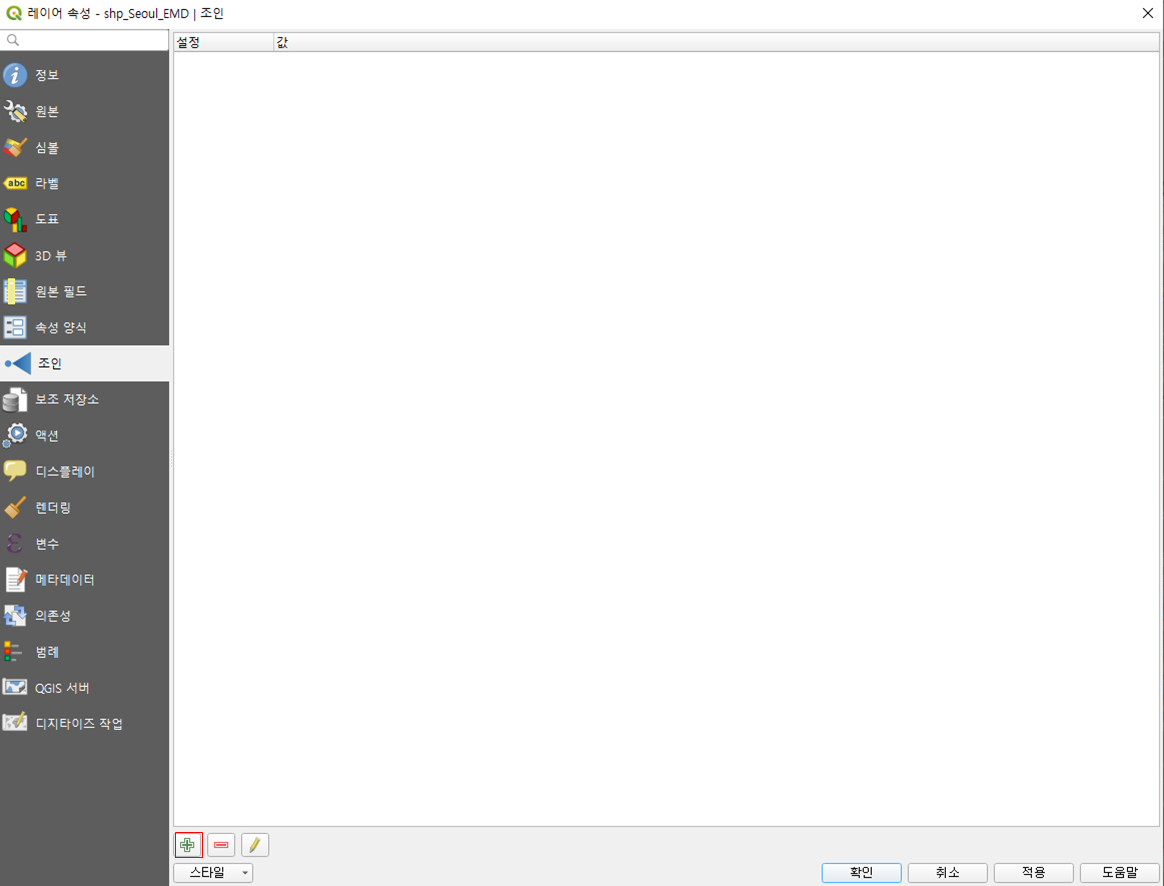
이번엔 법정동 레이어의 속성 창에서 조인 탭에 들어가보자. 여기서 다른 데이터와 연결할 수가 있다. + 버튼을 눌러서 조건을 추가하자.
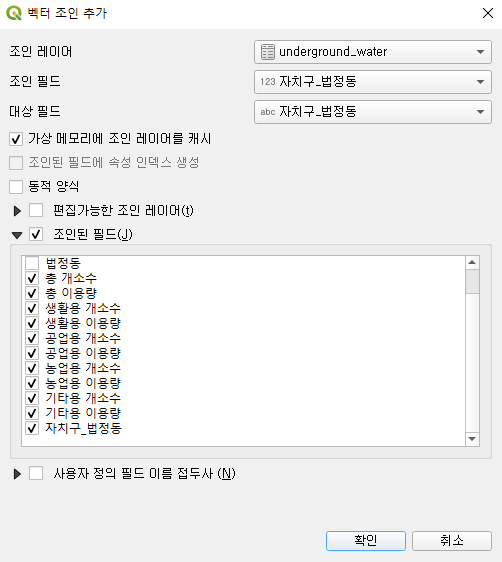
이 창을 유의해서 보자. 사실은 SQL의 join과 동일한 방식인데, 연결하고자 (조인) 하는 레이어를 설정하고, 그 레이어에서 어떤 데이터를 기준으로 조인할 것인지 (조인 필드), 조인 필드에 해당하는 지금 레이어의 데이터가 무엇인지 (대상 필드) 를 각각 설정해 준다.
그리고 실제로 어떤 데이터를 가져올 것인지 (조인된 필드) 아래에서 선택할 수가 있다. 기간이나 자치구/법정동과 같은 데이터는 어차피 있는 거니까 제끼고, 나머지 데이터를 쭉 연결해서 불러와 보자.
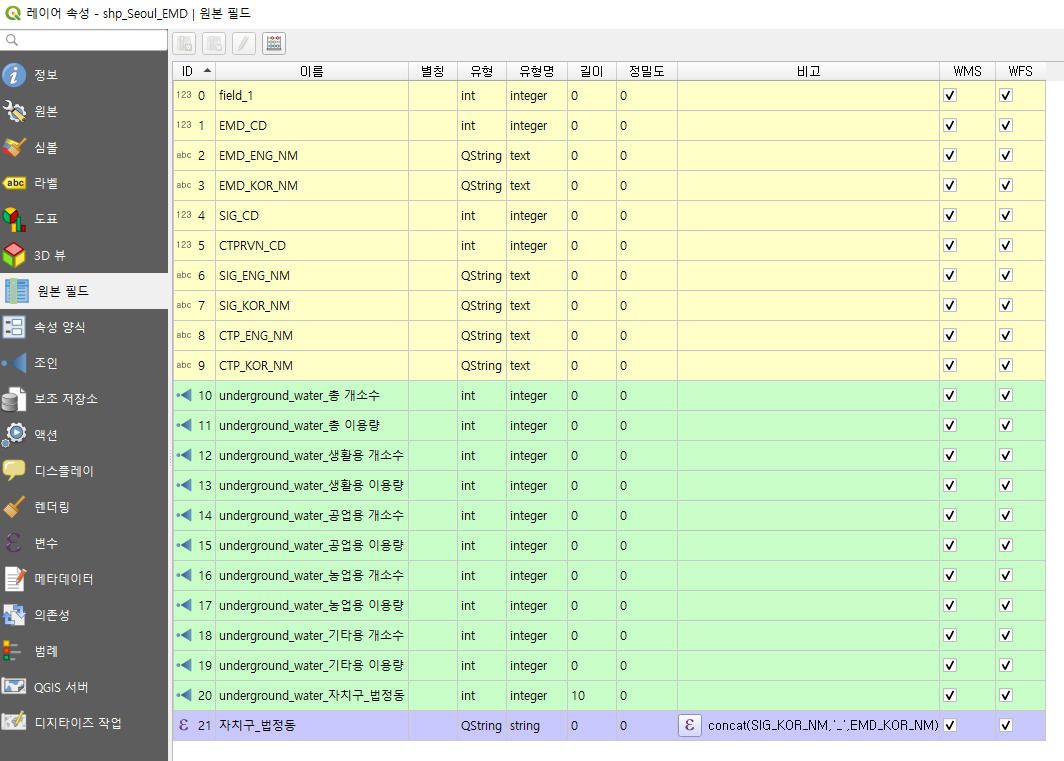
그리고 다시 "원본 필드" 탭으로 돌아가보면, 데이터가 쭉 추가된 것을 확인할 수 있다. 그럼 실제로 어떻게 연결되어 있는지 한번 보자.
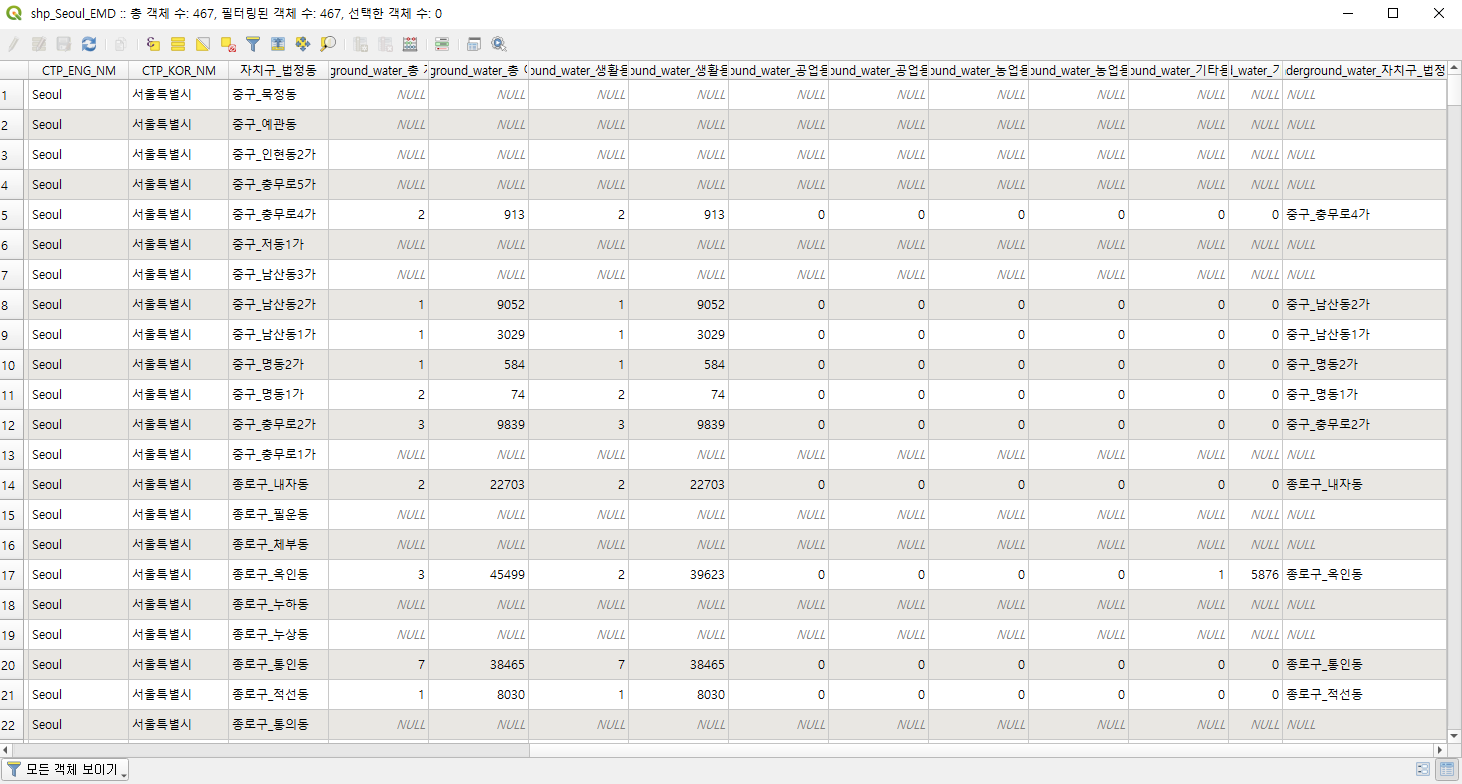
데이터가 붙긴 붙었다. 근데 뭔가... 중간에 NULL로 뻥뻥 뛴건 뭐지??
아까 위에서 행정동은 자주 바뀐다고 얘기를 했는데, 그거 때문에 그렇다. 지금 불러온 지하수 데이터는 2018년 기준 데이터고, 우리가 미리 얹어둔 법정동 경계 데이터는 2020년 기준이다. 지금은 있지만 과거에는 없었던 동은 저렇게 뻥뻥 비어있게 된다.
아마 쭉 내려보면 알 텐데, 그래도 대부분 잘 연결이 된 걸 확인할 수 있을 것이다. 이제 그러면 뭔가 시각적으로 한번 표현을 해보자.
시각화
사실 데이터를 저렇게 숫자로 줄줄이 읽는 사람이 얼마나 되겠는가? 그냥 한눈에 딱 봐서 아 이거네 싶은 걸 누구나 좋아한다.

위의 그래프는 나폴레옹이 러시아에 침공했을 때 병력의 변화를 그래프로 나타낸 건데, 저거만 봐도 얼마나 대참패를 했는지 한눈에 알 수가 있다. 역시 보이는 게 이뻐야 하는 것. 잘 알아볼 수 있는 시각화는 엄청 중요한 거 같다.
그럼 우리의 문제로 돌아와서, 각 동별 지하수 사용량을 시각화해보자.
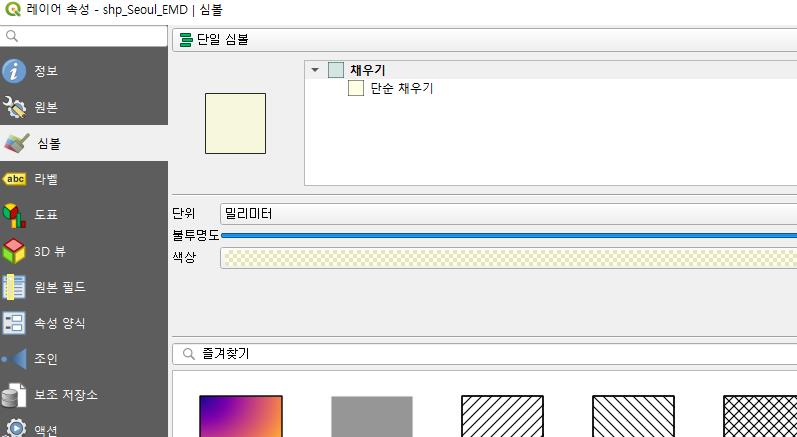
위의 심볼 탭에서 "단일 심볼" 을 클릭하면 몇가지 선택지가 나온다. 그 중에 "단계 구분" 을 선택하자.
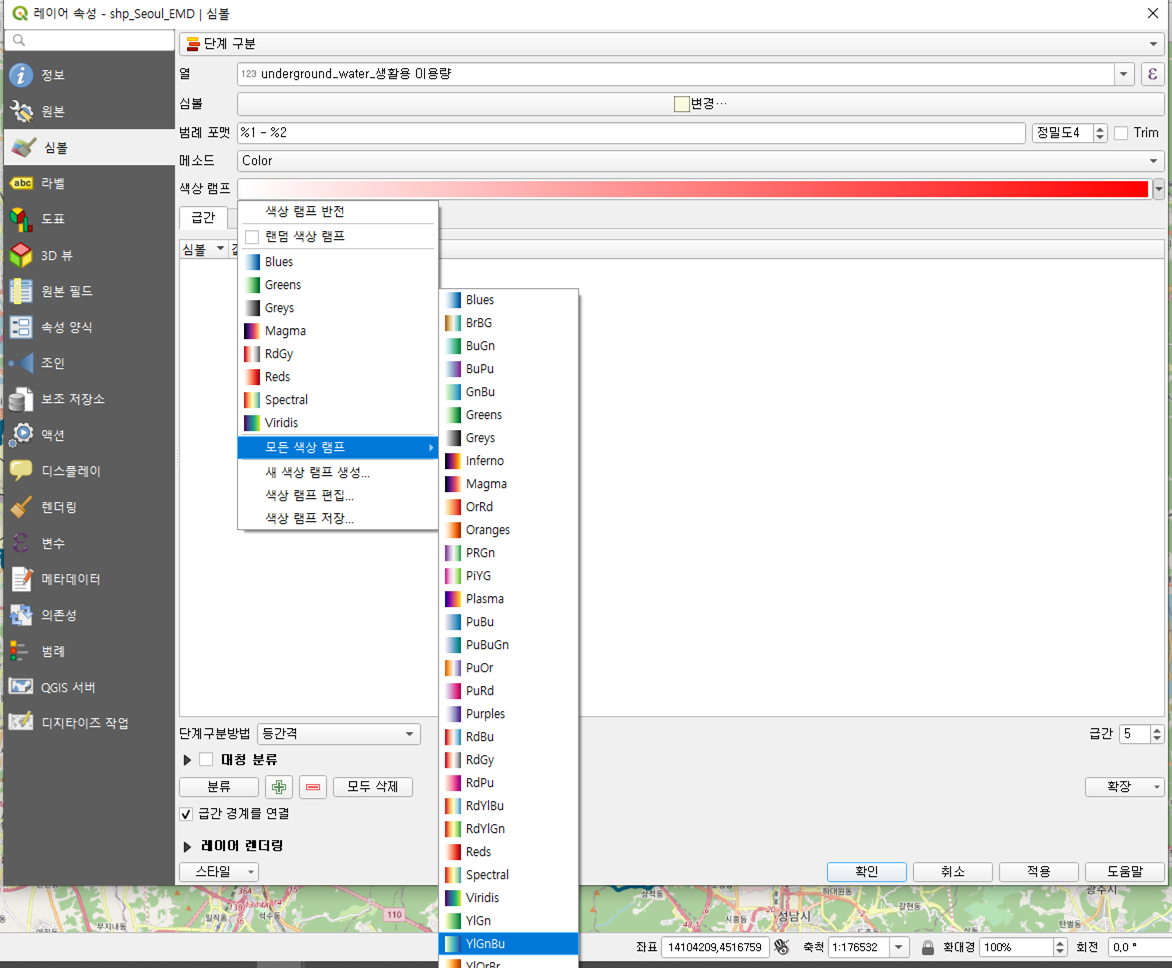
우선 위와 같이 설정한다. 생활용 이용량을 한번 보자. 색상 램프는 어떤 식으로 표현할지를 선택하는 건데, 뭐 빨간 색도 강렬해서 좋긴 한데... 일단 YlGnBu 로 선택해서 좀 부드럽게 표현해보자.
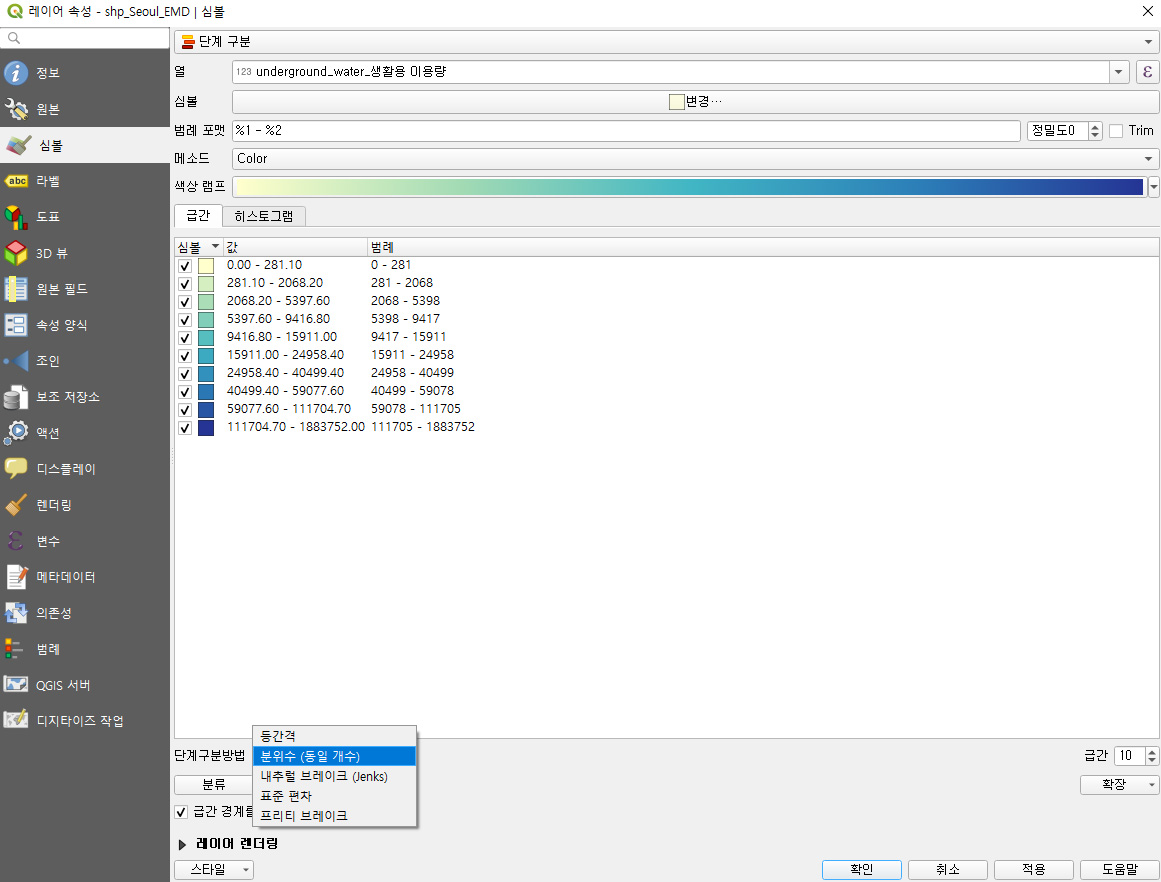
그다음 단계 구분 방법을 선택한다. 여러가지 방법이 있는데, 각 방법에 대한 설명은 마찬가지로 다음 글에 하고, 일단은 분위수를 선택해서 급간은 10 (몇 개 구간으로 보여줄 것인가) 정도로 선택해보자. 그리고 적용!
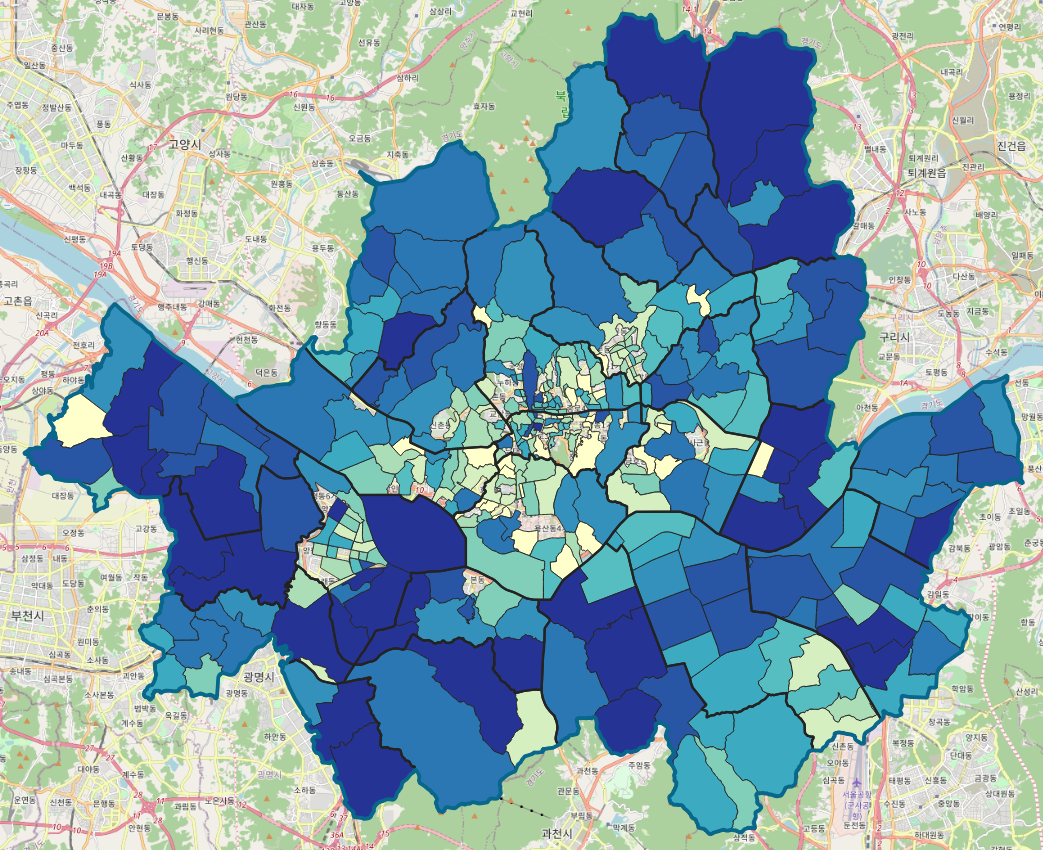
진한 파란색일수록 지하수를 많이 쓰는 지역이고, 노란색일 수록 안쓰는 지역이다.
* 아하.. 도심일수록 잘 안쓰고 산이 많으면 많이들 쓰네
* 아니 전부 시퍼런데 이렇게 많이 쓰는 거야?
* 중간에 뻥뻥 빈 데는 뭐지?
산지일수록 당연히 지하수를 많이들 쓰긴 할 텐데 전부 이렇게 시퍼렇게 표현되니까, 뭔가 맞게 된 건지 의심이 든다. 아래에서 이 부분을 한번 바꿔보고, 중간에 뻥뻥 빈 곳은 아까 데이터가 연결되지 못했던 곳들. 2018년에는 없었던 동이다. (명칭이 달랐거나) 그래서 데이터를 매칭하는 작업이 사실은 굉장히 중요하다. 아까처럼 빈 상태로 두면 안되고... 뭔가 다른 값으로 바꿔 준다든지 하는.
일단은 예시니까 이대로 보자. 좀아까 단계 구분 방법을 "분위수"로 선택했는데, 이번에는 다른 걸로 바꿔보자.
* 등간격
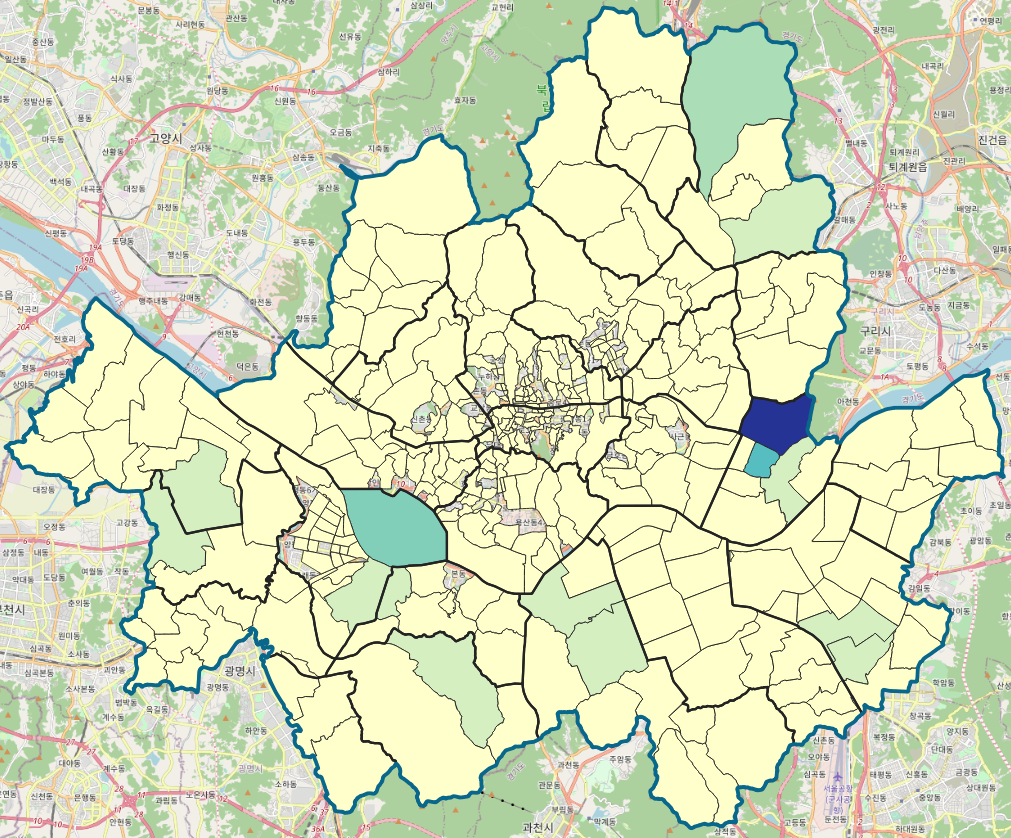
* 내추럴 브레이크
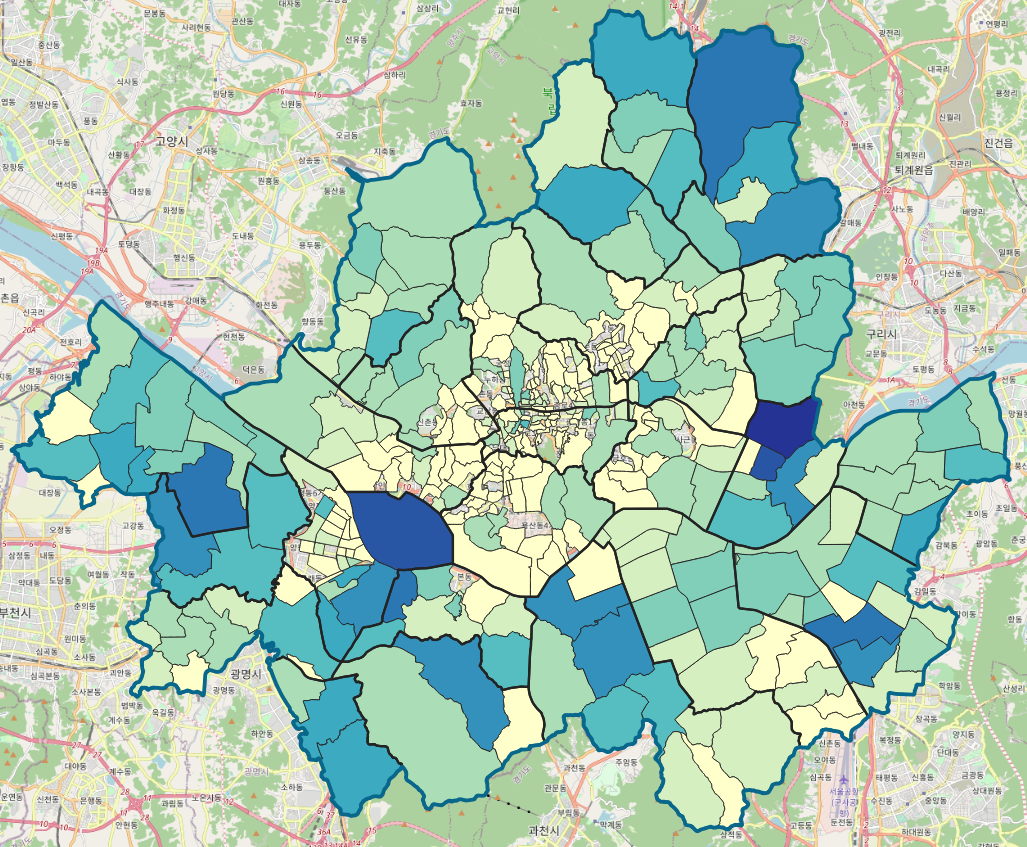
단계를 구분하는 방식에 따라서 이렇게 시각화가 다르다. 이 내추럴 브레이크라고 하는 게 GIS 시각화하는데 많이 쓰인다고 한다. 사실 알고 보면 K-means clustering 의 한 종류로 볼 수 있는 거 같던데, 다음 글에서 이 내용도 같이 한번 설명해보겠다.
일단 오늘 소개한 내용은
* 지도 데이터를 지역별로 저장하기
* 지도 데이터에 다른 데이터 연결하기
* 연결된 데이터를 시각화하기
이정도로 마무리한다. 다음 글에서는 아래 내용을 다루려고 한다.
* 법정동과 행정동 매칭하기
* 단계 구분 방식 개요 및 내추럴 브레이크 코드 소개




댓글